











Computer Science Engineering (CSE) Exam > Computer Science Engineering (CSE) Questions > Consider the following translation scheme. S ...
Start Learning for Free

Consider the following translation scheme. S → ER R → *E{print("*");}R | ε E → F + E {print("+");} | F F → (S) | id {print(id.value);} Here id is a token that represents an integer and id.value represents the corresponding integer value. For an input '2 * 3 + 4', this translation scheme prints
- a)2 * 3 + 4
- b)2 * +3 4
- c)2 3 * 4 +
- d)2 3 4+*
Correct answer is option 'D'. Can you explain this answer?
| FREE This question is part of | Download PDF Attempt this Test |
Verified Answer
Consider the following translation scheme. S → ER R → *E{p...
Background Required to solve the question - Syntax Directed Translation and Parse Tree Construction.
xplanation : We are given L-Attributed Syntax Directed Translation as semantic actions like printf statements are inserted anywhere on the RHS of production (R → *E{print(“*”);}R). After constructing the parse tree as shown below from the given grammar, we will follow depth first order left to right evaluation in order to generate the final output.
Parse Tree:
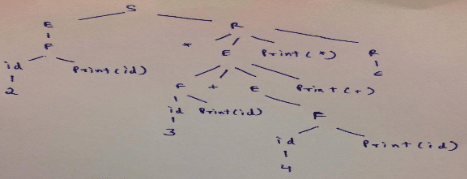
Just follow the arrows in the picture (This is actually Depth first left to right evaluation) and the moment we take exit from any child which is printf statement in this question, we print that symbol which can be a integer value or ‘*’ or ‘+’.
Evaluation :
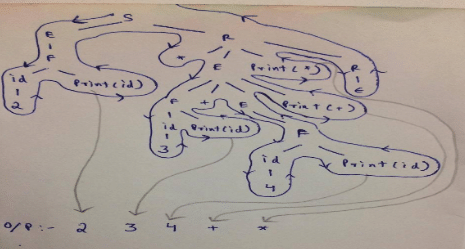
Most Upvoted Answer
Consider the following translation scheme. S → ER R → *E{p...
Explanation:
The given translation scheme represents a grammar for a simple arithmetic expression language. This grammar consists of non-terminal symbols (S, E, F) and terminal symbols (ER, *, (, ), id).
The translation scheme defines the translation rules for each non-terminal symbol. Let's analyze the translation rules one by one.
Translation Rule 1: S ER R *E{print(*);}R
This rule states that when S is encountered, it should be followed by ER and R. The translation for this rule is to print the result of the expression E followed by the string " * ", and then recursively apply the translation rule for R.
Translation Rule 2: E F E {print( );}
This rule states that when E is encountered, it should be followed by F and E. The translation for this rule is to print the result of the expression F followed by a space, and then recursively apply the translation rule for E.
Translation Rule 3: F F (S)
This rule states that when F is encountered, it should be followed by F and (S). The translation for this rule is to recursively apply the translation rule for F, followed by the translation for (S).
Translation Rule 4: id {print(id.value);}
This rule states that when id is encountered, it should be followed by the string " {print(id.value);} ". The translation for this rule is to print the value of the id.
Now let's apply the translation scheme to the given input: 2 * 3 4.
1. Start with the non-terminal symbol S.
2. Apply the translation rule S ER R *E{print(*);}R.
3. Print the result of the expression E (which is 2) followed by " * ".
4. Apply the translation rule R.
5. Apply the translation rule E F E {print( );}.
6. Print the result of the expression F (which is 3) followed by a space.
7. Apply the translation rule E F E {print( );}.
8. Print the result of the expression F (which is 4) followed by a space.
9. Apply the translation rule E F E {print( );}.
10. No more non-terminal symbols to expand.
11. The final output is "2 * 3 4".
Therefore, the correct answer is option 'D', which is "2 3 4 *".
The given translation scheme represents a grammar for a simple arithmetic expression language. This grammar consists of non-terminal symbols (S, E, F) and terminal symbols (ER, *, (, ), id).
The translation scheme defines the translation rules for each non-terminal symbol. Let's analyze the translation rules one by one.
Translation Rule 1: S ER R *E{print(*);}R
This rule states that when S is encountered, it should be followed by ER and R. The translation for this rule is to print the result of the expression E followed by the string " * ", and then recursively apply the translation rule for R.
Translation Rule 2: E F E {print( );}
This rule states that when E is encountered, it should be followed by F and E. The translation for this rule is to print the result of the expression F followed by a space, and then recursively apply the translation rule for E.
Translation Rule 3: F F (S)
This rule states that when F is encountered, it should be followed by F and (S). The translation for this rule is to recursively apply the translation rule for F, followed by the translation for (S).
Translation Rule 4: id {print(id.value);}
This rule states that when id is encountered, it should be followed by the string " {print(id.value);} ". The translation for this rule is to print the value of the id.
Now let's apply the translation scheme to the given input: 2 * 3 4.
1. Start with the non-terminal symbol S.
2. Apply the translation rule S ER R *E{print(*);}R.
3. Print the result of the expression E (which is 2) followed by " * ".
4. Apply the translation rule R.
5. Apply the translation rule E F E {print( );}.
6. Print the result of the expression F (which is 3) followed by a space.
7. Apply the translation rule E F E {print( );}.
8. Print the result of the expression F (which is 4) followed by a space.
9. Apply the translation rule E F E {print( );}.
10. No more non-terminal symbols to expand.
11. The final output is "2 * 3 4".
Therefore, the correct answer is option 'D', which is "2 3 4 *".
Attention Computer Science Engineering (CSE) Students!
To make sure you are not studying endlessly, EduRev has designed Computer Science Engineering (CSE) study material, with Structured Courses, Videos, & Test Series. Plus get personalized analysis, doubt solving and improvement plans to achieve a great score in Computer Science Engineering (CSE).


|
Explore Courses for Computer Science Engineering (CSE) exam
|
|
Similar Computer Science Engineering (CSE) Doubts


Top Courses for Computer Science Engineering (CSE)View all





Consider the following translation scheme. S → ER R → *E{print("*");}R | ε E → F + E {print("+");} | F F → (S) | id {print(id.value);} Here id is a token that represents an integer and id.value represents the corresponding integer value. For an input '2 * 3 + 4', this translation scheme printsa)2 * 3 + 4b)2 * +3 4c)2 3 * 4 +d)2 3 4+*Correct answer is option 'D'. Can you explain this answer?
Question Description
Consider the following translation scheme. S → ER R → *E{print("*");}R | ε E → F + E {print("+");} | F F → (S) | id {print(id.value);} Here id is a token that represents an integer and id.value represents the corresponding integer value. For an input '2 * 3 + 4', this translation scheme printsa)2 * 3 + 4b)2 * +3 4c)2 3 * 4 +d)2 3 4+*Correct answer is option 'D'. Can you explain this answer? for Computer Science Engineering (CSE) 2024 is part of Computer Science Engineering (CSE) preparation. The Question and answers have been prepared according to the Computer Science Engineering (CSE) exam syllabus. Information about Consider the following translation scheme. S → ER R → *E{print("*");}R | ε E → F + E {print("+");} | F F → (S) | id {print(id.value);} Here id is a token that represents an integer and id.value represents the corresponding integer value. For an input '2 * 3 + 4', this translation scheme printsa)2 * 3 + 4b)2 * +3 4c)2 3 * 4 +d)2 3 4+*Correct answer is option 'D'. Can you explain this answer? covers all topics & solutions for Computer Science Engineering (CSE) 2024 Exam. Find important definitions, questions, meanings, examples, exercises and tests below for Consider the following translation scheme. S → ER R → *E{print("*");}R | ε E → F + E {print("+");} | F F → (S) | id {print(id.value);} Here id is a token that represents an integer and id.value represents the corresponding integer value. For an input '2 * 3 + 4', this translation scheme printsa)2 * 3 + 4b)2 * +3 4c)2 3 * 4 +d)2 3 4+*Correct answer is option 'D'. Can you explain this answer?.
Consider the following translation scheme. S → ER R → *E{print("*");}R | ε E → F + E {print("+");} | F F → (S) | id {print(id.value);} Here id is a token that represents an integer and id.value represents the corresponding integer value. For an input '2 * 3 + 4', this translation scheme printsa)2 * 3 + 4b)2 * +3 4c)2 3 * 4 +d)2 3 4+*Correct answer is option 'D'. Can you explain this answer? for Computer Science Engineering (CSE) 2024 is part of Computer Science Engineering (CSE) preparation. The Question and answers have been prepared according to the Computer Science Engineering (CSE) exam syllabus. Information about Consider the following translation scheme. S → ER R → *E{print("*");}R | ε E → F + E {print("+");} | F F → (S) | id {print(id.value);} Here id is a token that represents an integer and id.value represents the corresponding integer value. For an input '2 * 3 + 4', this translation scheme printsa)2 * 3 + 4b)2 * +3 4c)2 3 * 4 +d)2 3 4+*Correct answer is option 'D'. Can you explain this answer? covers all topics & solutions for Computer Science Engineering (CSE) 2024 Exam. Find important definitions, questions, meanings, examples, exercises and tests below for Consider the following translation scheme. S → ER R → *E{print("*");}R | ε E → F + E {print("+");} | F F → (S) | id {print(id.value);} Here id is a token that represents an integer and id.value represents the corresponding integer value. For an input '2 * 3 + 4', this translation scheme printsa)2 * 3 + 4b)2 * +3 4c)2 3 * 4 +d)2 3 4+*Correct answer is option 'D'. Can you explain this answer?.
Solutions for Consider the following translation scheme. S → ER R → *E{print("*");}R | ε E → F + E {print("+");} | F F → (S) | id {print(id.value);} Here id is a token that represents an integer and id.value represents the corresponding integer value. For an input '2 * 3 + 4', this translation scheme printsa)2 * 3 + 4b)2 * +3 4c)2 3 * 4 +d)2 3 4+*Correct answer is option 'D'. Can you explain this answer? in English & in Hindi are available as part of our courses for Computer Science Engineering (CSE).
Download more important topics, notes, lectures and mock test series for Computer Science Engineering (CSE) Exam by signing up for free.
Here you can find the meaning of Consider the following translation scheme. S → ER R → *E{print("*");}R | ε E → F + E {print("+");} | F F → (S) | id {print(id.value);} Here id is a token that represents an integer and id.value represents the corresponding integer value. For an input '2 * 3 + 4', this translation scheme printsa)2 * 3 + 4b)2 * +3 4c)2 3 * 4 +d)2 3 4+*Correct answer is option 'D'. Can you explain this answer? defined & explained in the simplest way possible. Besides giving the explanation of
Consider the following translation scheme. S → ER R → *E{print("*");}R | ε E → F + E {print("+");} | F F → (S) | id {print(id.value);} Here id is a token that represents an integer and id.value represents the corresponding integer value. For an input '2 * 3 + 4', this translation scheme printsa)2 * 3 + 4b)2 * +3 4c)2 3 * 4 +d)2 3 4+*Correct answer is option 'D'. Can you explain this answer?, a detailed solution for Consider the following translation scheme. S → ER R → *E{print("*");}R | ε E → F + E {print("+");} | F F → (S) | id {print(id.value);} Here id is a token that represents an integer and id.value represents the corresponding integer value. For an input '2 * 3 + 4', this translation scheme printsa)2 * 3 + 4b)2 * +3 4c)2 3 * 4 +d)2 3 4+*Correct answer is option 'D'. Can you explain this answer? has been provided alongside types of Consider the following translation scheme. S → ER R → *E{print("*");}R | ε E → F + E {print("+");} | F F → (S) | id {print(id.value);} Here id is a token that represents an integer and id.value represents the corresponding integer value. For an input '2 * 3 + 4', this translation scheme printsa)2 * 3 + 4b)2 * +3 4c)2 3 * 4 +d)2 3 4+*Correct answer is option 'D'. Can you explain this answer? theory, EduRev gives you an
ample number of questions to practice Consider the following translation scheme. S → ER R → *E{print("*");}R | ε E → F + E {print("+");} | F F → (S) | id {print(id.value);} Here id is a token that represents an integer and id.value represents the corresponding integer value. For an input '2 * 3 + 4', this translation scheme printsa)2 * 3 + 4b)2 * +3 4c)2 3 * 4 +d)2 3 4+*Correct answer is option 'D'. Can you explain this answer? tests, examples and also practice Computer Science Engineering (CSE) tests.
|
|
Explore Courses for Computer Science Engineering (CSE) exam
|
|
Suggested Free Tests
Signup for Free!
Signup to see your scores go up within 7 days! Learn & Practice with 1000+ FREE Notes, Videos & Tests.




|
© EduRev
|
Education Revolution
|



Follow Us
|








Signup to see your scores
go up within 7 days!
Access 1000+ FREE Docs, Videos and Tests
Takes less than 10 seconds to signup